How Tryg has leveraged Prisma to democratize data


Tryg saved huge amounts of time thanks to its “360” Data Broker platform that accelerated development cycles by removing the overhead incurred by configuring environments manually. Prisma was the critical technology that enabled them to democratize billions of records from different data sources.
Tryg is one of the largest non-life insurance companies of the Nordic region, offering a wide range of insurances for the private, commercial, and corporate markets - and handling more than 1 million claims each year.
Like many enterprises, Tryg faced the need to become more data-centric while battling the pains of siloing data.
Tryg had a range of different data sources spread across different countries. Tryg's data models of the sources couldn't be reused because they were built over decades, with varying definitions of the same concepts. This led to many fixes, workarounds, and compromises.
Integrating the data from one of these sources would have required Tryg to harmonize it, which is a time-consuming and error-prone task. The ultimate goal was to make the data available to everyone, including those unfamiliar with SQL and entity-relationship diagrams.
One of the primary technologies that have enabled Tryg to accomplish data democratization is Prisma.
Data democratisation with Tryg 360
Achieving data democratization required the implementation of a proprietary platform. Therefore, Tryg implemented and launched the Data Broker platform in production called Tryg 360.
Tryg 360 enabled their developers to spin up environments by simply clicking a button. This called the applications they needed, allowed them to visualize the data in real-time, share the application URL with other users, etc. This has helped them achieve every developer's dream: focus on writing value-adding code instead of managing all the backend setup and suffer long wait times for an environment to load.
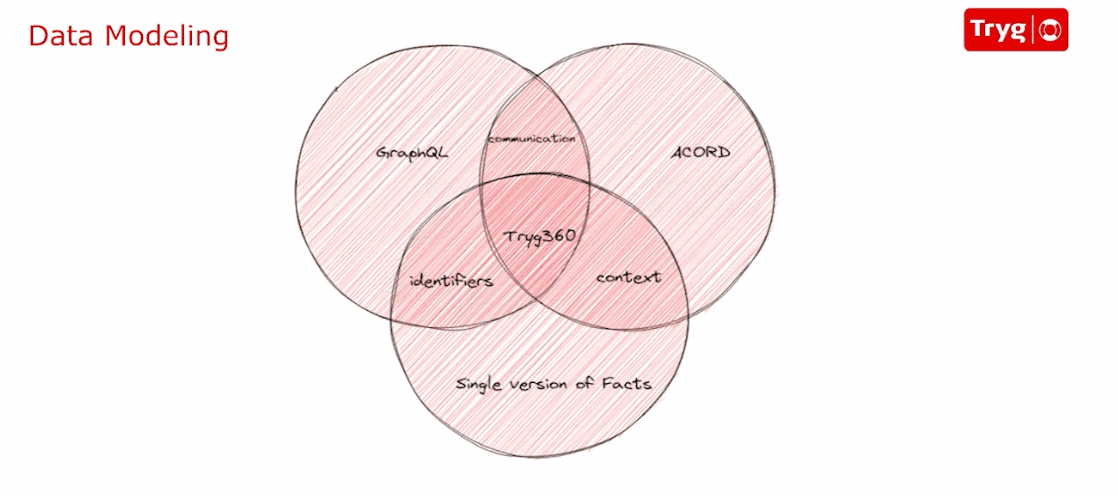
To accomplish this, Tryg adopted Prisma for it's ability to auto-generate the database client, and GraphQL APIs that their developers would interact with.
The generator API determines which assets are created when the prisma generate command is run.
Auto-generation of the Prisma Client and GraphQL API is essential to Tryg because they have very complex models with massive amounts of data – some schema files being 10k lines long with over a million characters!
After generating their Prisma Client, Tryg uses Pal.js to autogenerate a GraphQL API that other developers and users of the system interact with. This is important to them as it automates hand-coding the GraphQL resolvers for them. Pal.js is a generator that allows the generation of GraphQL CRUD resolvers based on the Prisma Schema.
"Prisma is a huge technical enabler for us"
Automation with Prisma
Tryg's infrastructure setup is relatively complex as it involves several steps to deploy a complete environment via CI. The process involves loading data from different systems and databases, transforming it into a canonical model, and loading it into a single database.
Tryg had the following requirements regarding deploying new environments:
- Autogenerate the database based on the schema
- Autogenerate the Prisma Client API based on the schema
- Deploy any application, source, or combination of applications
- Do it with 1-click
"Our setup with Prisma enabled us to generate everything from code and ensure our developers can iterate very quickly."
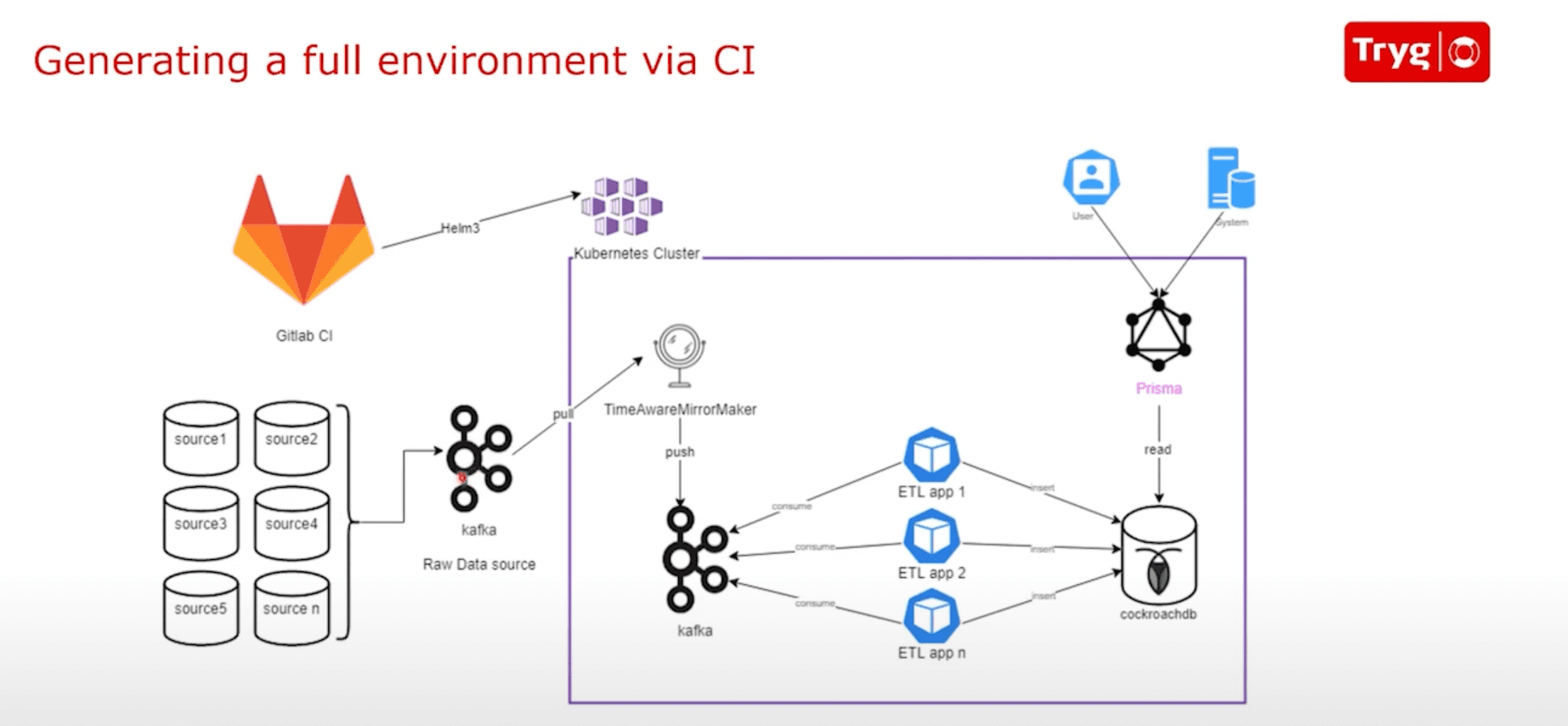
Resources required to deploy an environment are defined in Helm charts. Kubernetes takes care of provisioning necessary resources. The steps involved while provisioning resources include:
- Live streaming the raw data from different sources without any transformation. This ensures that developers can work with the live data when the environment is created.
- Deploying the Time-Aware MirrorMaker – responsible for synchronizing data correctly from different data sources and pipelines at any time. This is an implementation of Apache Kafka's MirrorMaker.
- Deploying a local Kafka cluster to load the data they need instead of loading data from all the sources.
- Deploying the applications needed for the particular environment
- Data transformation by the deployed applications and loading the data into a Cockroach database
- Deploying an app using Prisma that accesses a specific Cockroach database
- Autogenerating resolvers and type definitions based on the Prisma Schema
Since CockroachDB is compatible with the PostgreSQL wire protocol, Prisma Client can communicate with it even if Prisma doesn't provide full support for CockroachDB yet.
With Prisma, Tryg has managed to generate their database client and GraphQL API quickly – allowing fast iteration, unifying their data sources with a single schema, and simplifying data access for systems and users.
Tryg and Prisma's Vision
By unifying their separate data sources into a unified place and automating the complex processes of making data accessible to development teams, Tryg has pioneered an approach that perfectly aligns with our vision for the Prisma Data Platform.
Prisma's goal is to democratize the Application Data Platform concept that companies like Facebook, Twitter, and Airbnb have built for themselves. We want to enable development teams and organizations of all sizes to embrace modern development workflows, by keeping data access flexible, secure, and effortlessly scalable.
Learn more about our plans for Prisma Enterprise
Conclusion
Prisma has played a significant role in enabling Tryg to build the Tryg 360 platform. As a next step, Tryg is looking into techniques like event modeling to sharpen their domain model, how to think about events and how they are stored around a timeline, and we're eager to support them in their journey!
Listen to the full Tryg talk to learn more about:
- Lessons learned
- How the Time-Aware MirrorMaker works
- See a demo of Tryg & Prisma in action
To find out more about how Prisma can help your teams boost productivity, join the Prisma Slack community.
Keep reading

How One Founder Builds a Live Sports Platform Without a Database Team
How Xeito uses Prisma ORM and Prisma Postgres to ship live scoring, leagues, payments, and player workflows without a database team.


How Deno and Prisma Partnered to Power Per-Branch Databases
Deno Deploy integrates Prisma Postgres for instant per-branch databases, enabling seamless full-stack deployment and modern developer workflows.

Build your next app with Prisma
Start free. Scale when you’re ready.